Use your own text-to-speech provider with Anam avatars via audio passthrough mode.
Beta Feature: Audio passthrough mode is currently in beta. APIs may change as we continue to improve the integration.
Want to use ElevenLabs Agents with Anam? We recommend the server-side ElevenLabs integration instead—it’s simpler and has lower latency. This page covers the client-side approach for when you need direct control over the audio pipeline.
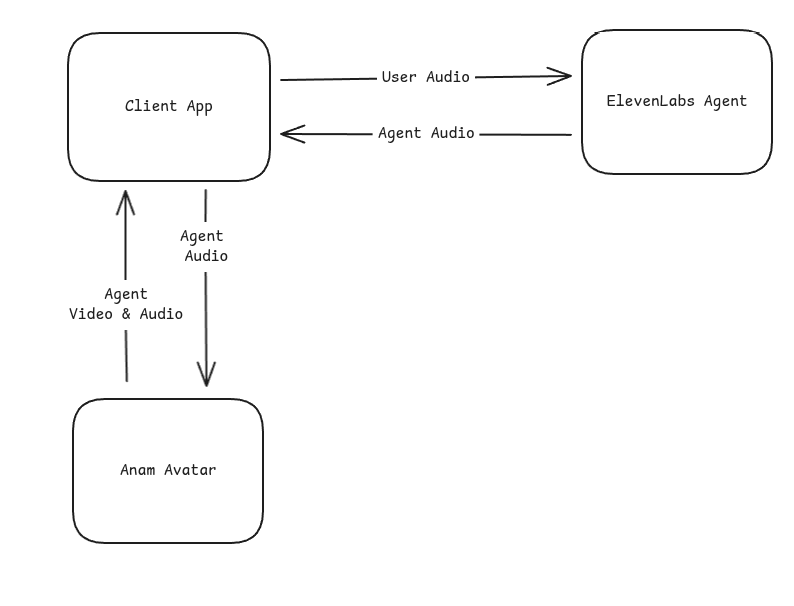
This guide shows how to use Anam’s audio passthrough mode to pipe externally-generated speech audio into an avatar for real-time lip-sync. The example below uses ElevenLabs Conversational AI as the TTS source, but the same pattern works with any TTS provider (Cartesia, PlayHT, Azure Speech, Google Cloud TTS, etc.)—you just need to deliver PCM audio chunks to the Anam SDK.
Your TTS must generate audio above realtime speed. If your TTS provider streams audio slower than 1x realtime, you will experience stutter and frame drops because Anam needs extra time to buffer and render the lip-sync animation. Most cloud TTS providers stream well above realtime, but verify this before going to production.
The integration uses Anam’s audio passthrough mode, where Anam renders an avatar that lip-syncs to audio you provide—without using Anam’s own AI or microphone input.
Bring Your Own Voice: Your TTS provider generates the speech audio. Anam renders the lip-synced avatar video.
Here’s the core pattern for connecting an external TTS source to Anam:
Copy
Ask AI
import { createClient } from "@anam-ai/js-sdk";// 1. Create Anam client with audio passthrough sessionconst anamClient = createClient(sessionToken, { disableInputAudio: true, // Your TTS provider handles microphone});await anamClient.streamToVideoElement("video-element");// 2. Create agent audio input streamconst audioInputStream = anamClient.createAgentAudioInputStream({ encoding: "pcm_s16le", sampleRate: 16000, channels: 1,});// 3. Connect to your TTS provider and forward audio// (ElevenLabs WebSocket shown here as an example)const ws = new WebSocket(`wss://api.elevenlabs.io/v1/convai/conversation?agent_id=${agentId}`);ws.onmessage = (event) => { const msg = JSON.parse(event.data); if (msg.type === "audio" && msg.audio_event?.audio_base_64) { // Forward audio chunks to Anam for lip-sync audioInputStream.sendAudioChunk(msg.audio_event.audio_base_64); } if (msg.type === "agent_response") { // Signal end of audio sequence audioInputStream.endSequence(); } if (msg.type === "interruption") { // Handle barge-in: stop the avatar animation and end the audio sequence anamClient.interruptPersona(); audioInputStream.endSequence(); }};
Creates a stream for sending audio chunks to the avatar for lip-sync. Must be called afterstreamToVideoElement() resolves (the session must be started first).
When a user speaks while the agent is talking (barge-in), your TTS provider sends an interruption event. Handle it by interrupting the avatar and ending the audio sequence:
interruptPersona() stops the avatar’s current lip-sync animation immediately. endSequence() tells the audio stream that the current sequence is done. Both are needed—without interruptPersona(), the avatar may continue playing buffered audio.
This integration combines two real-time services, which adds latency compared to using Anam’s turnkey solution:
Path
Typical Latency
User speech → ElevenLabs STT
200-400ms
ElevenLabs LLM processing
300-800ms
ElevenLabs TTS → Anam avatar
100-200ms
Total end-to-end
600-1400ms
For lower latency requirements, consider using Anam’s turnkey solution which handles STT, LLM, and TTS in an optimized pipeline, or the server-side ElevenLabs integration which reduces latency through server-to-server audio flow.